AWS Graviton ARM-64 vs Amazon X86-64 GRAND PRIX 2024. Round1: CPU Benchmark.

Abstract
This is a first post in series of AWS Graviton ARM-64 vs Amazon X86-64 GRAND PRIX 2024 where we will check different performance factors of Graviton, compare to classic x86. I will use own benchmarking tool assembled as docker image that is bootstrapped to both arm and x86 instances. At last Round we will deep dive into its implementation.
We will run standard sysbench test to stress different CPUs and check the scores for different scenarios.
Hypothesis to validate
- compare CPU-score utilization of x86 family
- compare CPU-score utilization of arm family
- compare CPU-score utilization between x86/arm
- see what is underlying CPU and real COREs used on machine
- check how single/multithreaded app consumes vCPUs
Instances Configuration used for testing
Instances are prepared for each CPU architecture with the following configurations. Containers are bootstrapped from docker image that has all benchmark tools installed and is compatible to both x86/arm architectures.
No side-car processes or applications are running on the container. There is a small <0.1% CPU overhead for established SSH session and terminal that controls operations.
Machines configuration is chosen with scaling factor x2 to measure how actual operations scale compared to scaling of vCPU.
| vCPU | memory | type |
|---|---|---|
| 0.25 | 0.5 | x86-64 |
| 0.5 | 1 | x86-64 |
| 1 | 2 | x86-64 |
| 2 | 4 | x86-64 |
| 4 | 8 | x86-64 |
| vCPU | memory | type |
|---|---|---|
| 0.25 | 0.5 | ARM-64 |
| 0.5 | 1 | ARM-64 |
| 1 | 2 | ARM-64 |
| 2 | 4 | ARM-64 |
| 4 | 8 | ARM-64 |
Test Scenario
Same suit of performance tests is run on each instance. Suit is assembled as docker image and is available at benchmark image: docker hub
- sysbench_cpu_1.csv - single thread Random numbers generation for 10 sec to get CPU score
- sysbench_cpu_2.csv - 2 threaded Random numbers generation for 10 sec to get CPU score
- sysbench_cpu_4.csv - 4 threaded Random numbers generation for 10 sec to get CPU score
- sysbench_cpu_8.csv - 8 threaded Random numbers generation for 10 sec to get CPU score
1/2/4/8 threaded modes are selected to verify the utilization of Cores for machines with different physical CPU and Hypervisor vCPU configurations.
Benchmark results of x86-64 instances:
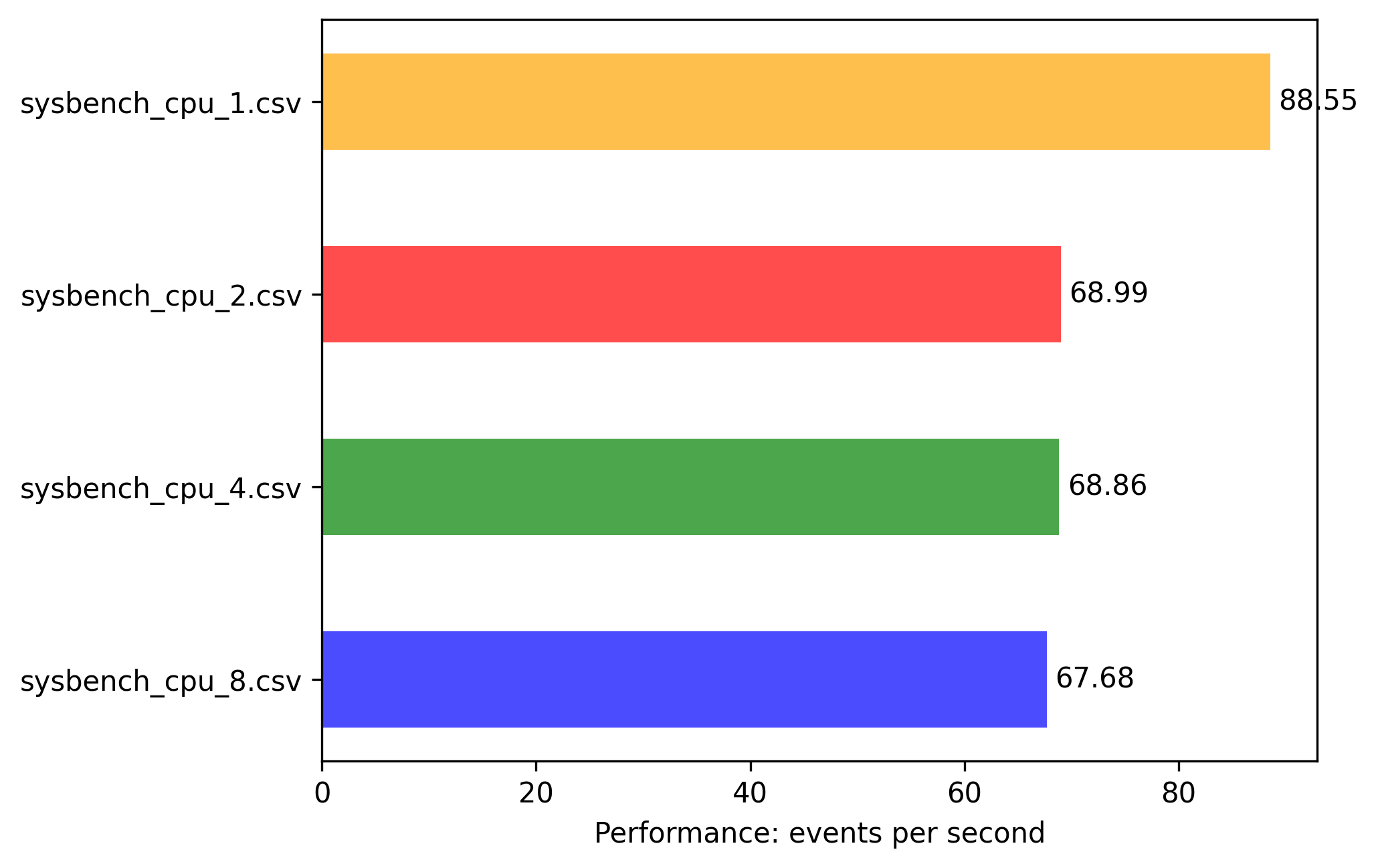 x86: 0.25vcpu 0.5G memory
x86: 0.25vcpu 0.5G memory
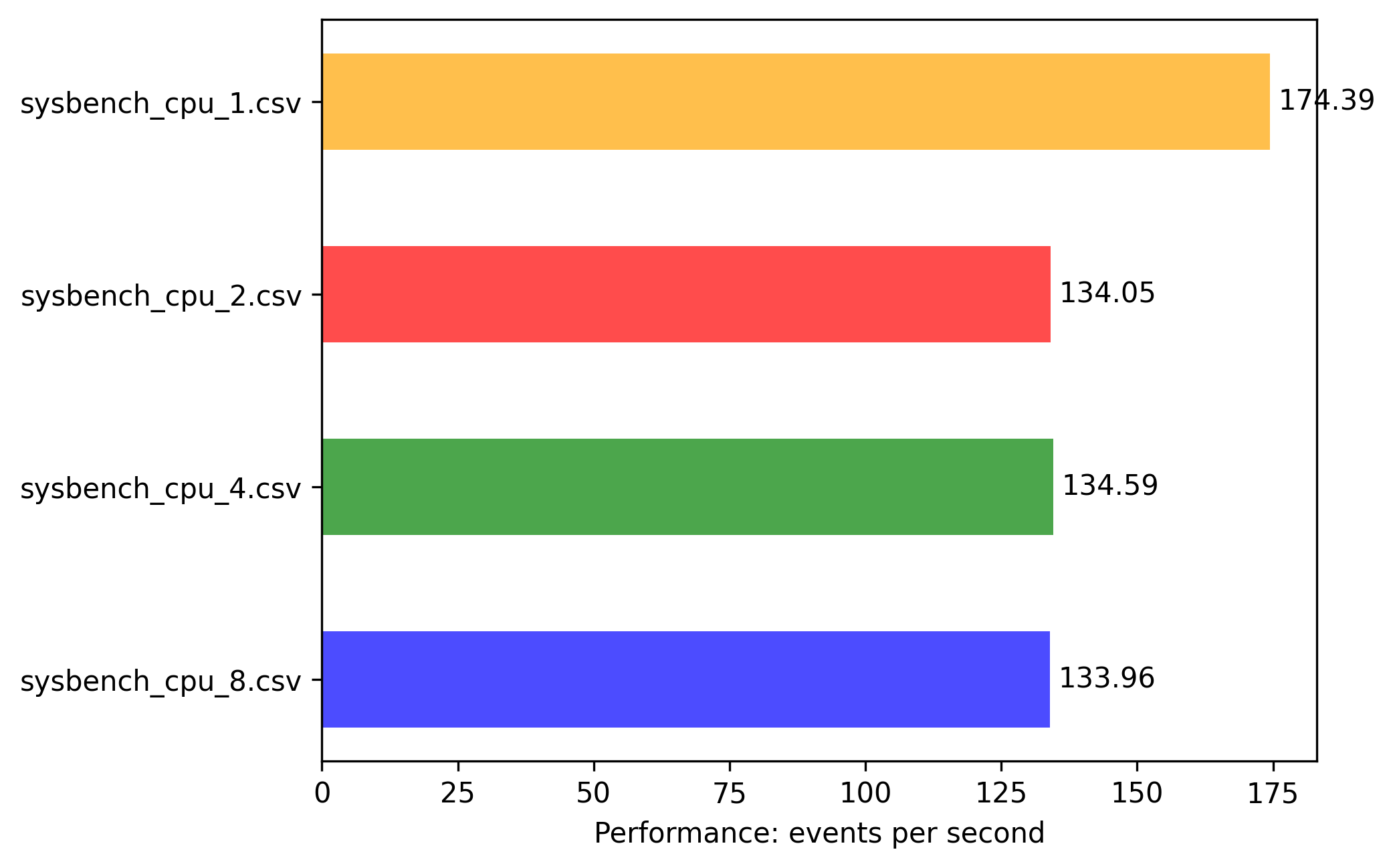 x86: 0.5vcpu 1G memory
x86: 0.5vcpu 1G memory
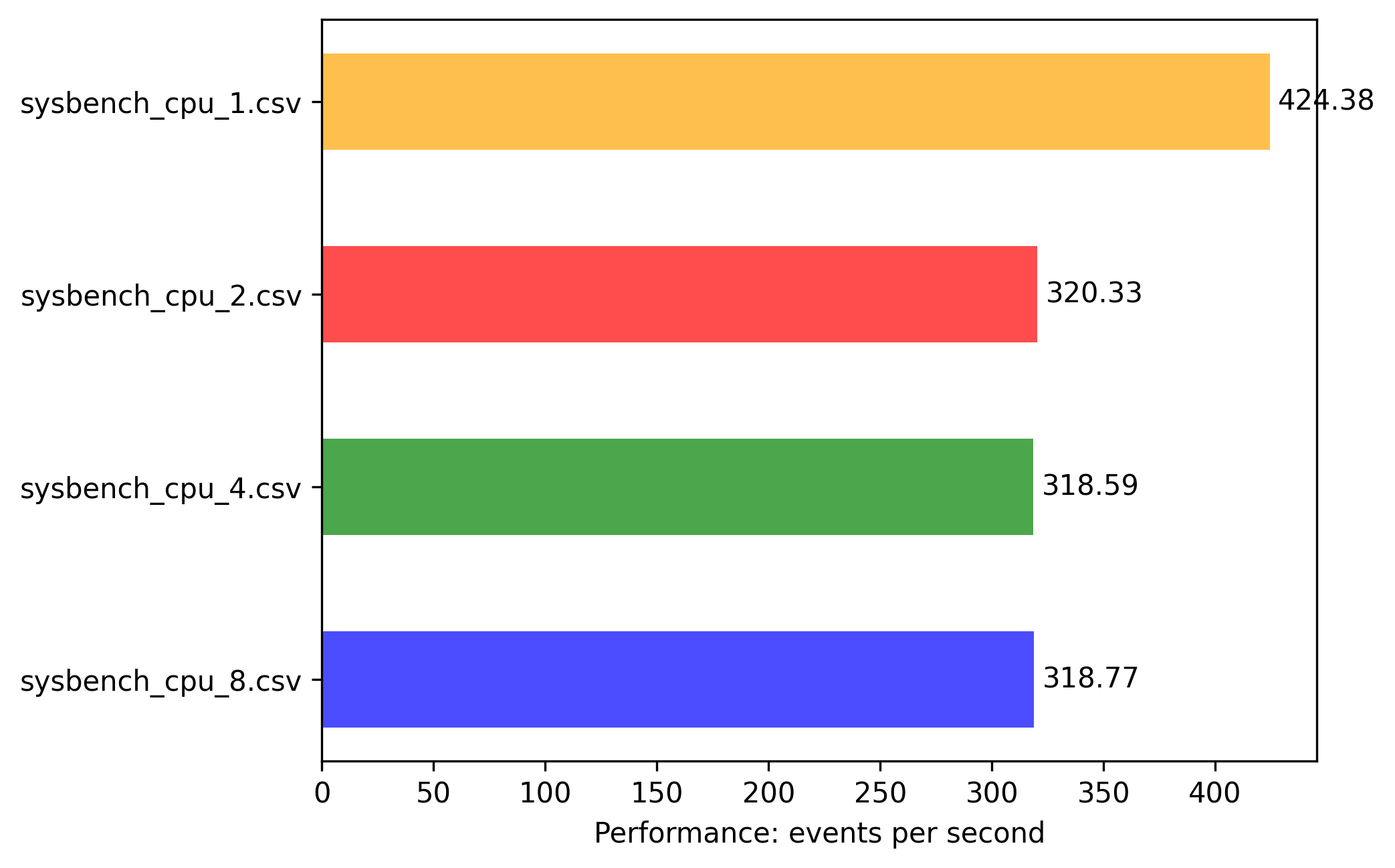 x86: 1vcpu 2G memory
x86: 1vcpu 2G memory
Till this point even we observe that 1-single-threaded application can utilize full capacity of all vCPU.
This line of experiments show that best performance is achieved by running single threaded workloads. If to scale to multithreaded mode we even observe the performance degradation.
Scale from 0.25 vCPU to 0.5vCPU went with 2x factor from 88.55 to 174.39 events/sec, but scale from 0.5vCPU to 1vCPU is not linear 174.39 to 424.38
Spoiler: even that on this machine there are actually 2 CORE attached (see later), still Amazon hypervisor fully utilizes all vCPU credits even to 1 core 1 threaded application. Bigger scale is because of different physical CPU used for 1vCPU machines (see later)
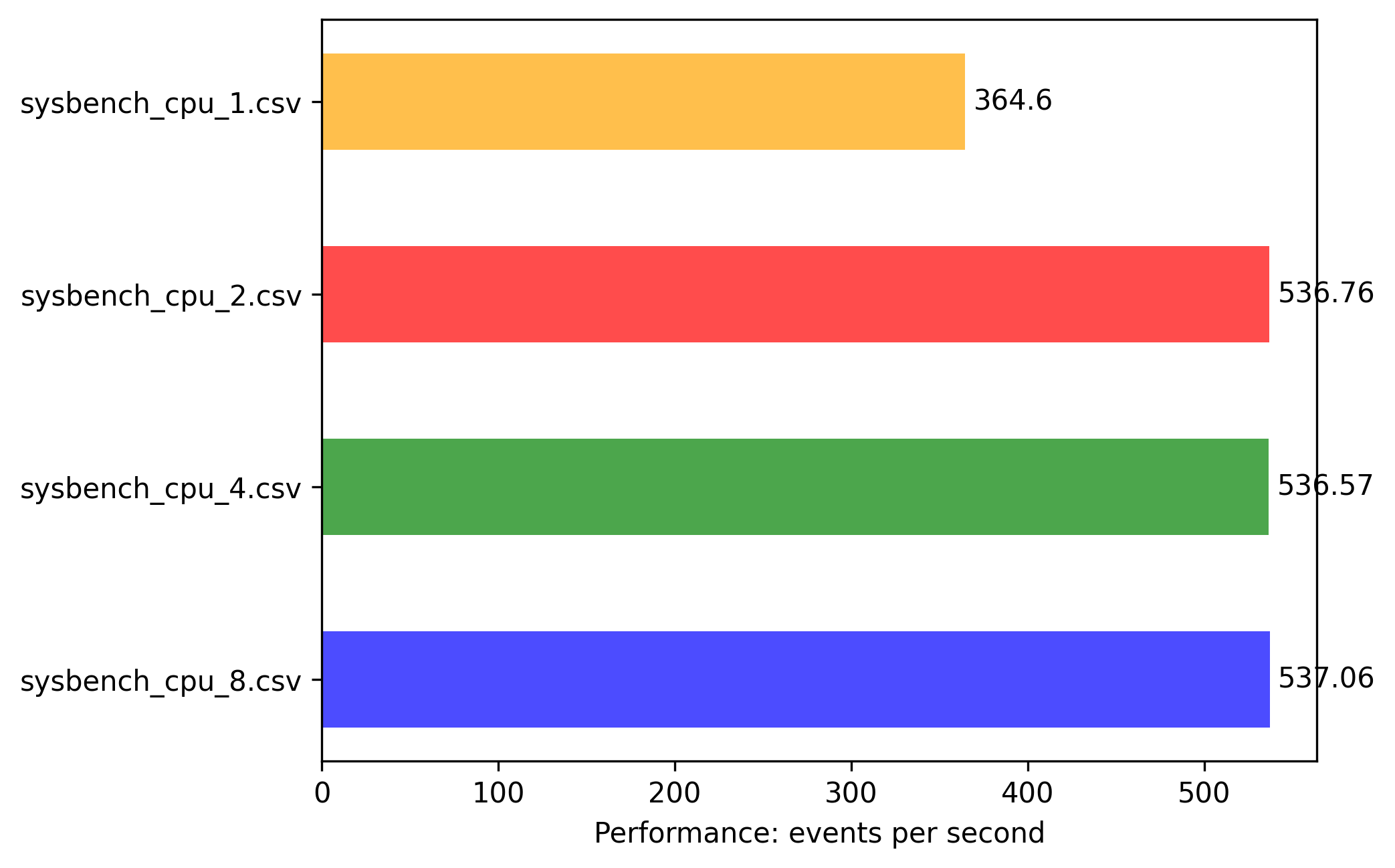 x86: 2vcpu 4G memory
x86: 2vcpu 4G memory
This is strange! 2vCPU is not scaled linear, the shift is very small. But here we can observe, that full vCPUs are not utilized evenly between cores, there is a limit of vCPU that can be consumed by single core if we are using single threaded application, and there is a spike in performance when using 2 threaded application.
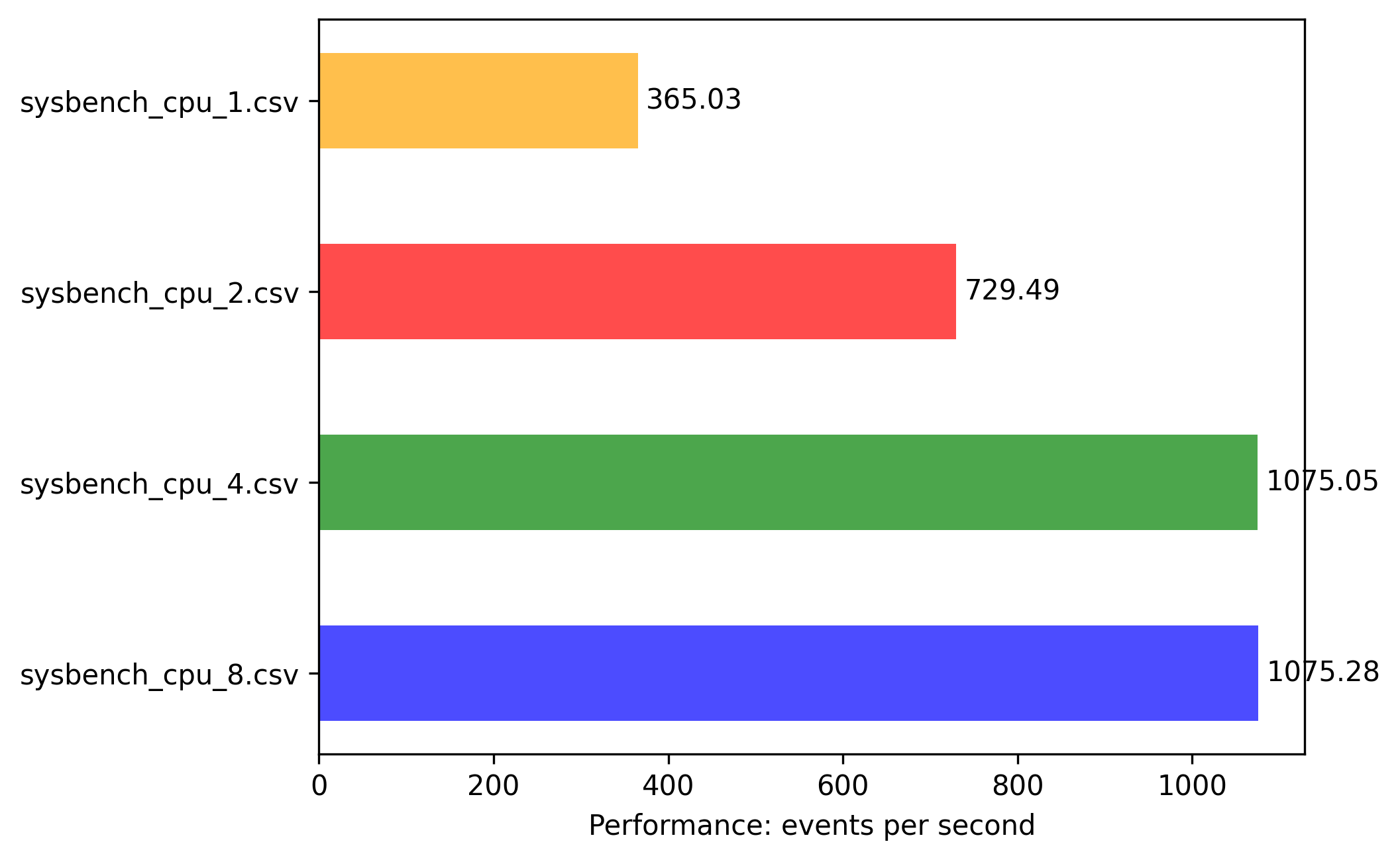 x86: 4vcpu 8G memory
x86: 4vcpu 8G memory
Here we see that 4 threaded application has more event/sec and scaling is fair enough 2x both with vCPU and events/sec. 4vCPU has double increase in events/sec compared to 2vCPU.
Benchmark results of arm-64 instances:
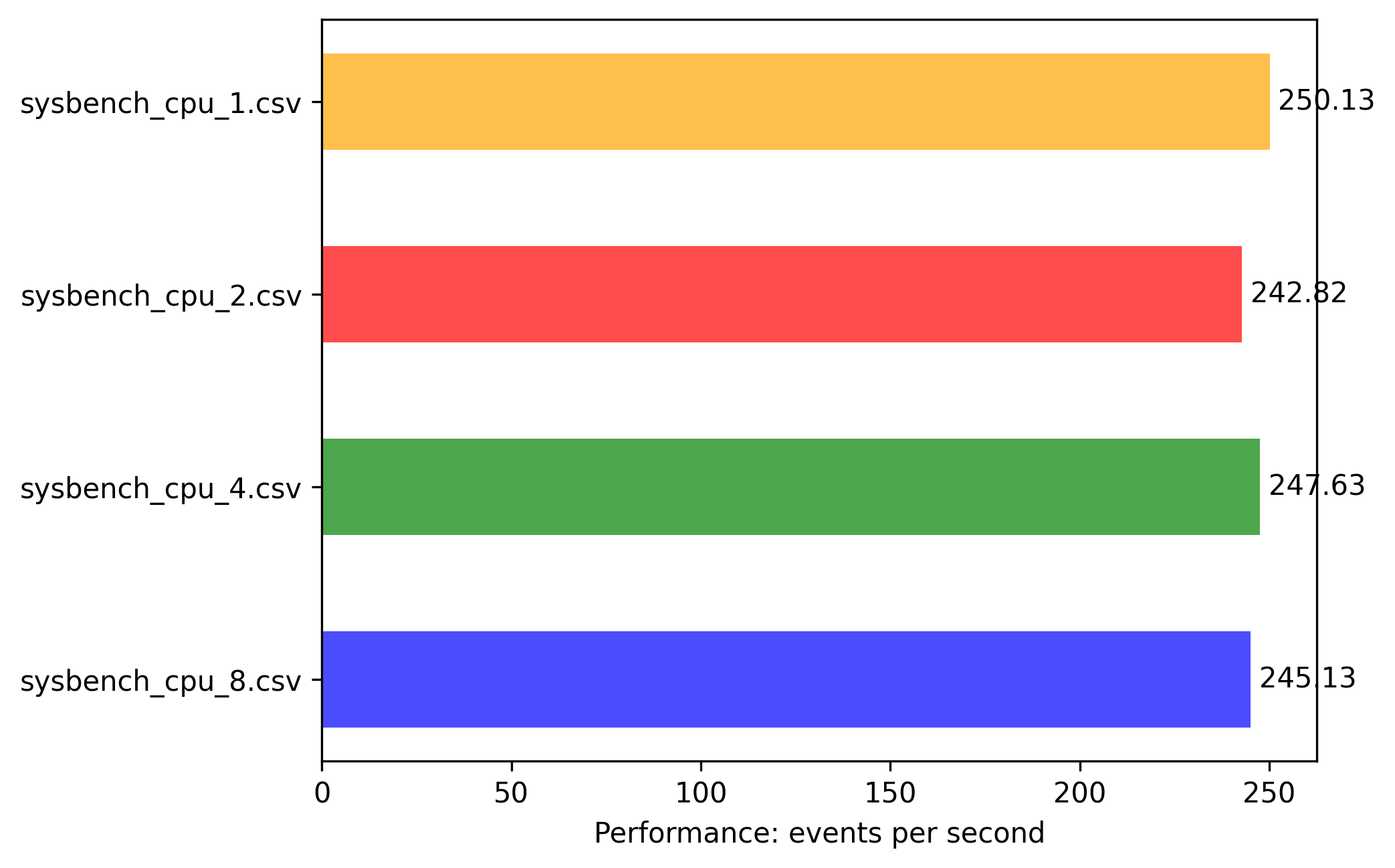 arm-64: 0.25vcpu 0.5G memory
arm-64: 0.25vcpu 0.5G memory
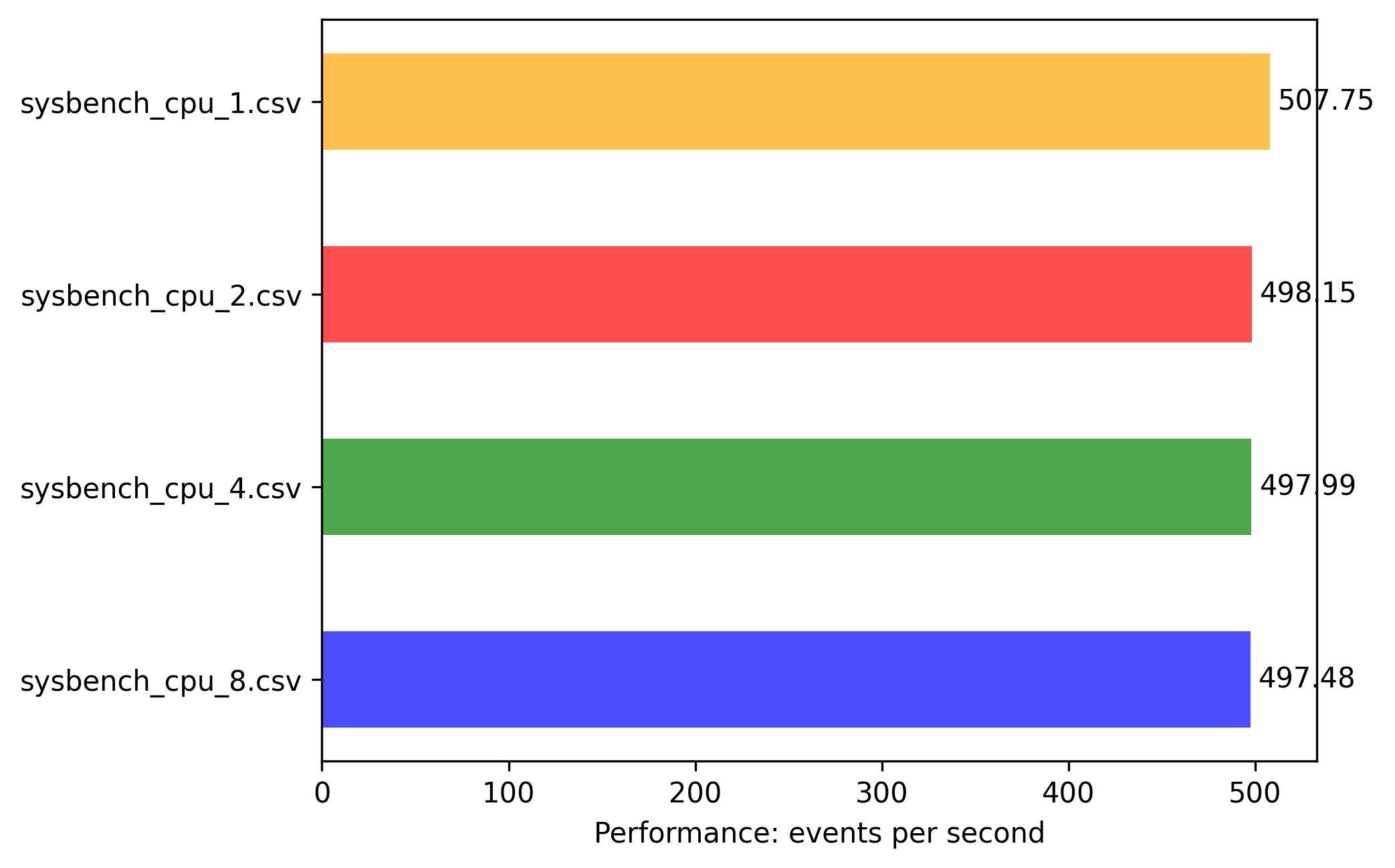 arm-64: 0.5vcpu 1G memory
arm-64: 0.5vcpu 1G memory
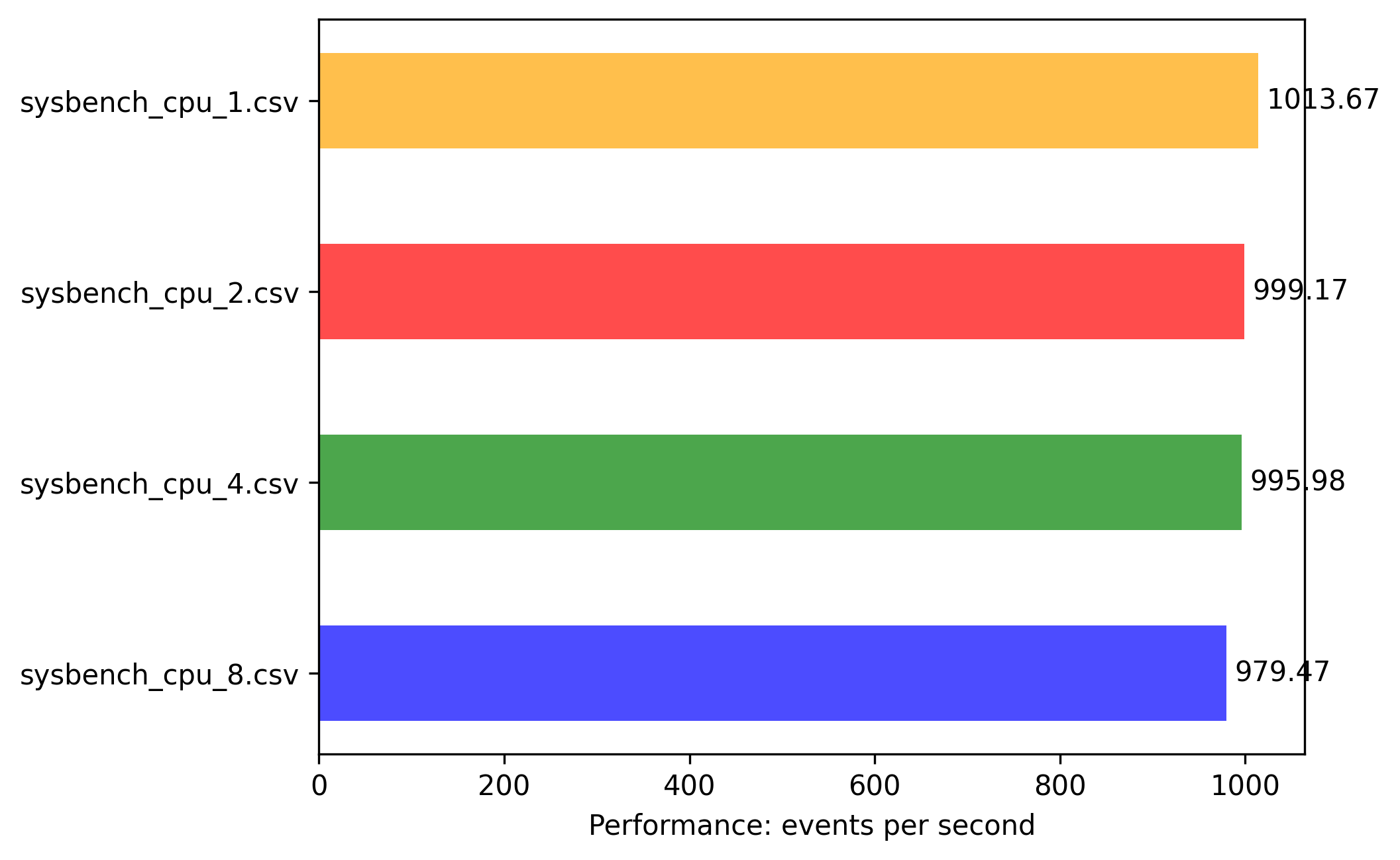 arm-64: 1vcpu 2G memory
arm-64: 1vcpu 2G memory
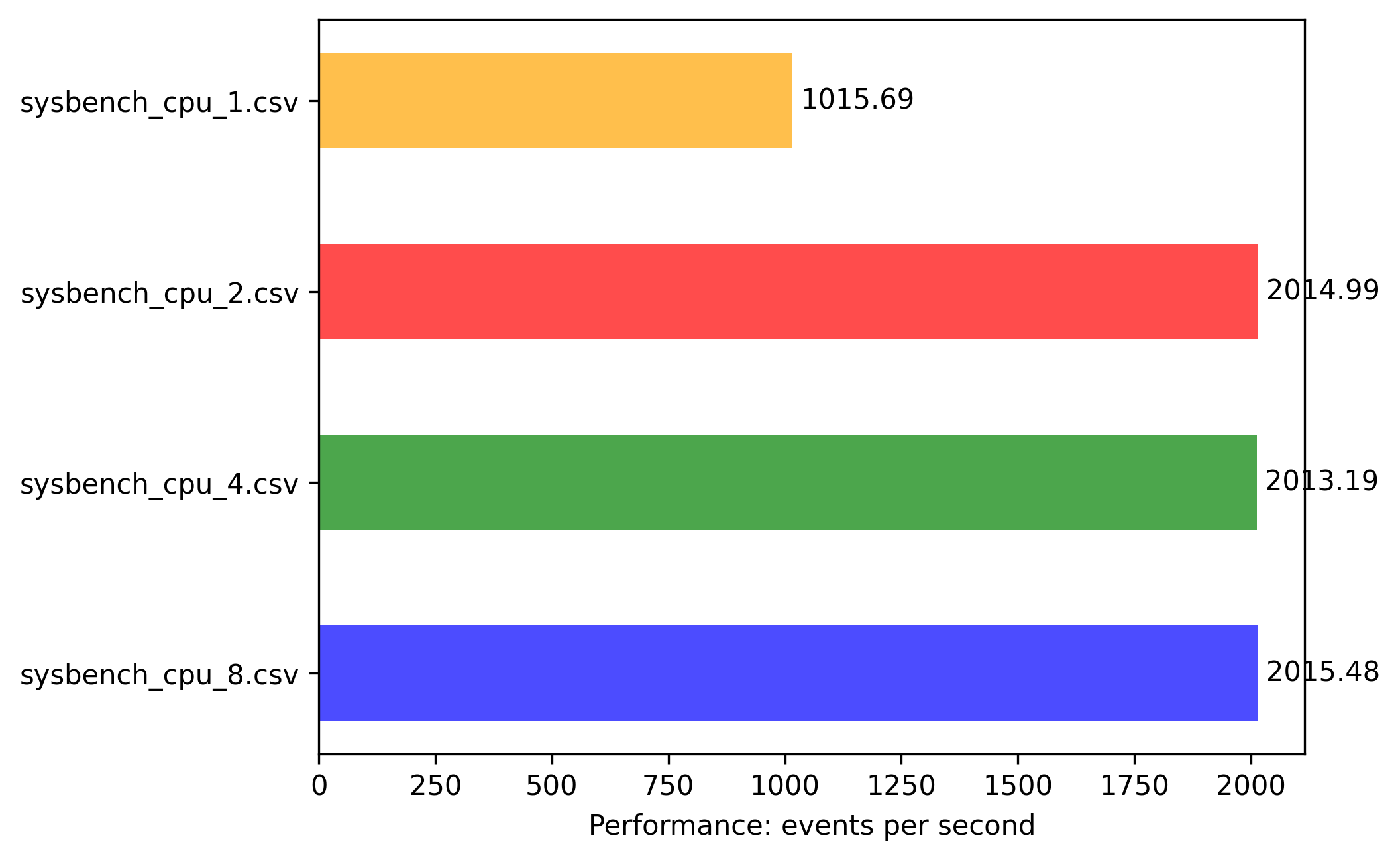 arm-64: 2vcpu 4G memory
arm-64: 2vcpu 4G memory
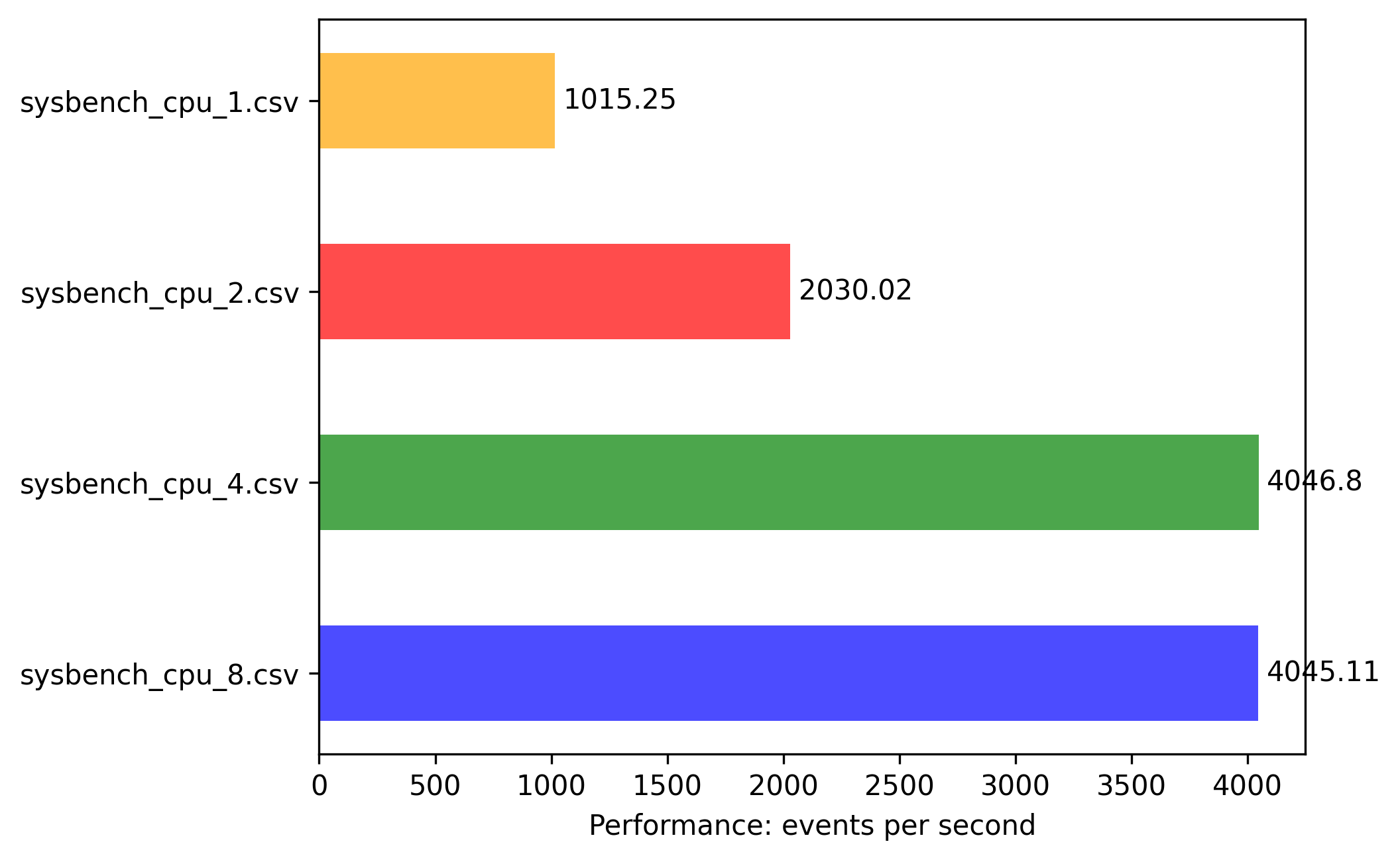 arm-64: 4vcpu 8G memory
arm-64: 4vcpu 8G memory
Results are more linear predictable and numbers are self explaining:
- all instances till 1vCPU can fully utilize 1 CORE with highest event/sec.
- scaling factor is as expected compared to vCPUs
- 2vCPU is 2x boost with 2 threaded app
- 4vCPU is 4x boost with 4 threaded app
And the biggest finding is that events/sec are much higher compared to same experiments on x86-64.
Physical COREs on the machine
Let’s explore the real COREs attached to Task and container to understand the parallelism possibilities and features of Amazon hyperscaler.
AWS x86 architecture
| vCPU | memory | type | COREs |
|---|---|---|---|
| 0.25 | 0.5 | x86-64 | 2x Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz |
| 0.5 | 1 | x86-64 | 2x Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz |
| 1 | 2 | x86-64 | 2x Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz |
| 2 | 4 | x86-64 | 2x Intel(R) Xeon(R) Platinum 8175M CPU @ 2.50GHz |
| 4 | 8 | x86-64 | 4x Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz |
We can observe that different CPUs are used in different configurations.
0.25, 0.5, 2 vCPU all are using 2 CORES of same processor family Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz. 1vCPU instances are using are using more powerful 2 cores 2x Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz. And what is strange that 4vCPU instance again using less productive Platinum 8259CL CPU @ 2.50GHz but with 4 COREs.
AWS Graviton
The Graviton2 CPU has 64 Neoverse N1 cores, with ARMv8.2-A ISA including 2×128 bit Neon, LSE, fp16, rcpc, dotprod, crypto. The vCPUs are physical cores in a single NUMA domain, running at 2.5 GHz
| vCPU | memory | type | COREs |
|---|---|---|---|
| 0.25 | 0.5 | ARM-64 | 2x BogoMIPS : 243.75 |
| 0.5 | 1 | ARM-64 | 2x BogoMIPS : 243.75 |
| 1 | 2 | ARM-64 | 2x BogoMIPS : 243.75 |
| 2 | 4 | ARM-64 | 2x BogoMIPS : 243.75 |
| 4 | 8 | ARM-64 | 4x BogoMIPS : 243.75 |
Graviton cores assignment follows the same pattern, with difference that there is no change of CPU family. So scaling should be more smoozer and predictive.
Scaling Factors Comparison
Performance scaling is much better for arm instances - we can observe perfect line with same angel. But for x86 instances there are some anomalies with bigger/smaller angel. Also arm performance with same vCPU is much higher compare to x86.
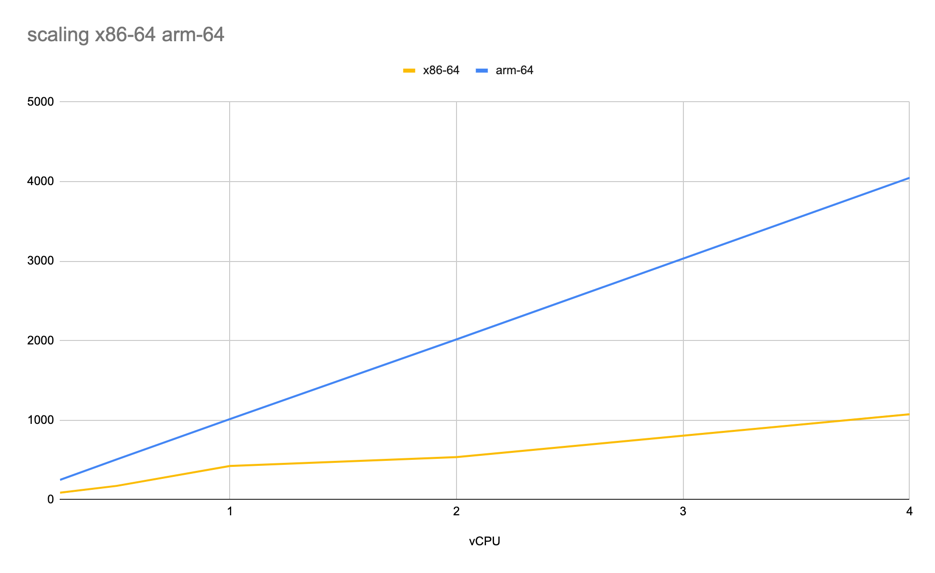 events/sec per vCPU for x86-64/arm-64
events/sec per vCPU for x86-64/arm-64
At the same time pricing scales linear compared to amount of vCPUs attached. ARM scaling is less expensive.
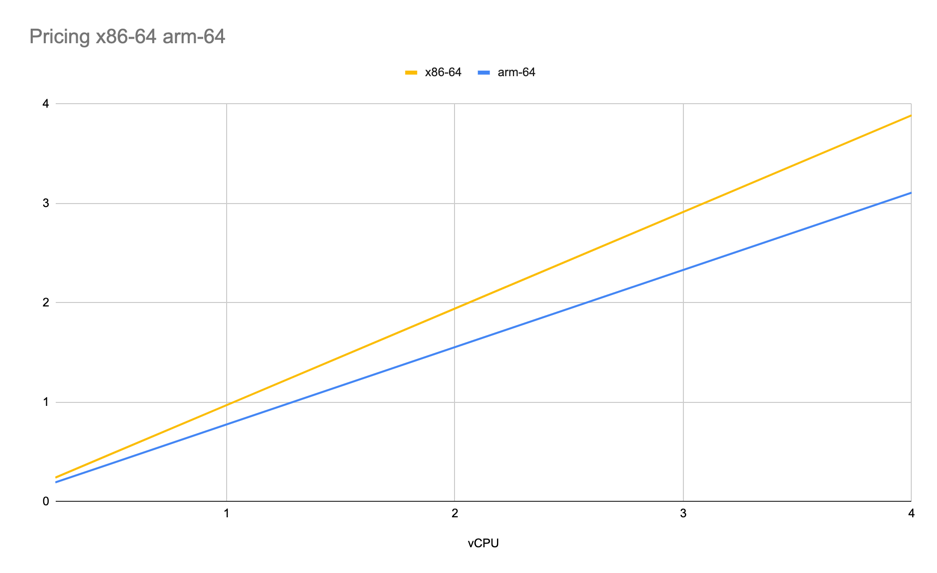 Price per day per vCPU for x86-64/arm-64
Price per day per vCPU for x86-64/arm-64
Scaling of vCPU for arm-64 graviton follows the same trend both from events/sec and pricing, but for x86-64 price scales faster compared to performance, much faster 😊.
Key TakeAways:
- know you application details for best tune CPU and instance family selection
- vertical scaling of vCPU in case you have big CPU utilization will not help if you are using
nodejsor single threaded app - perform real benchmarks on you hardware and compare the results
- there is different amount of Cores, CPU families attached to different vCPU families so scaling is not as expected